FreeBSD SMPngが完了、性能が劇的に改善 72
ストーリー by mhatta
ビフォーアフター 部門より
ビフォーアフター 部門より
uyota 曰く、
2000年から続けられていたFreeBSDの次世代SMP対応プロジェクト、通称SMPngが完了し、劇的な性能改善を実現したようだ。
Kris Kennaway氏の実験結果によると、同じ8コアの amd64 システム上において、最新のLinuxカーネルと、ULEスケジューラに更にパッチをいくつか当てた 7.0-CURRENTの両方でMySQLのトランザクション/秒を計測したところ、クライアント数が 8 までならばLinuxの方が僅かに上回るが、それ以上になると今回改良されたFreeBSDのパフォーマンスが勝ることが分かった。特に14クライアントを越えた後のLiunxは無惨な結果となり、1スレッド並にまで性能が劣化するが、FreeBSDはそれ以降も安定した性能を発揮できたという(グラフ)。
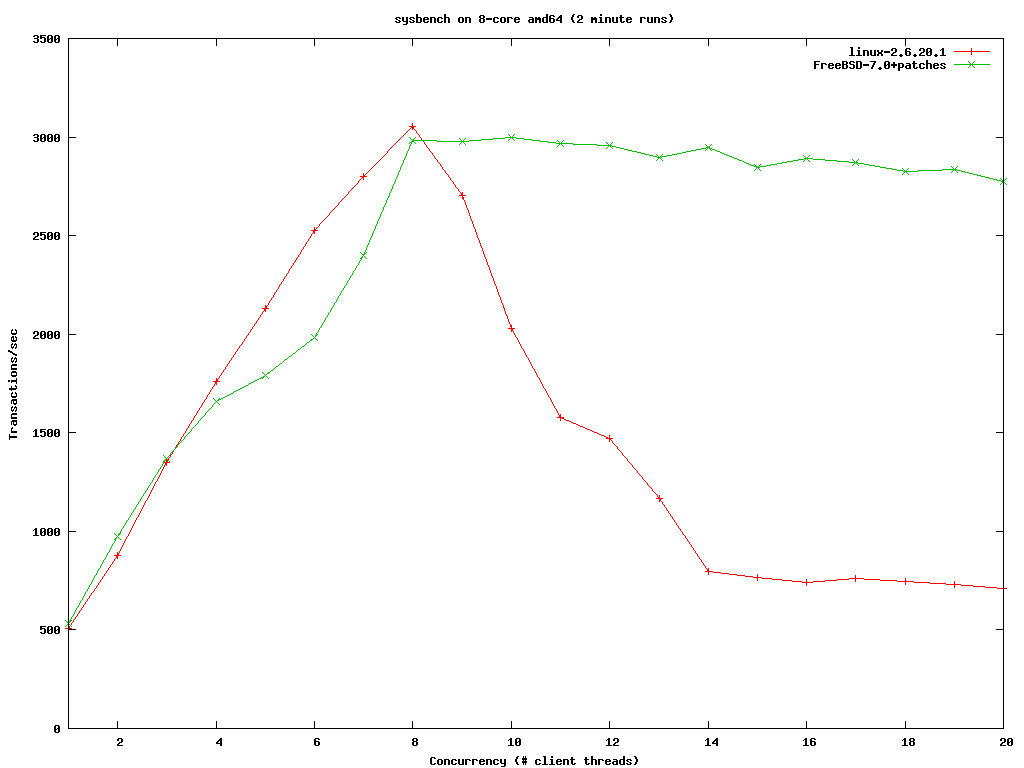{kind=link}
本当に劇的に改善したの? (スコア:3, 興味深い)
タレコミにリンクが貼ってあるグラフ [freebsd.org]ですが,
このグラフを見た限りでは,すくなくとも性能が劇的に改善したように見えません.場合によっては,Linuxの方が性能が良いようにさえ見えます.
まず,縦軸のピークは linux です.
(意地悪な言い方をすれば) アプリケーション側でチューニングを行えば Linux のほうが性能がでることになります
次に,グラフの左側,並列度が実CPU数よりも低い場合は Linuxのほうが1割以上速いという結果が出ています.
タレコミ中では”僅かに上回る”と言っていますが,CPUのマルチコア化が進んでいる状況を考えると,並列度が低い場合に1割以上性能が劣る事実は,FreeBSDがLinuxに劣る欠点として認識すべきです.
グラフの右側も含めて,グラフ全体を見ても,
- 高負荷時のスループット BSD が有利
- 低負荷時のスループット Linux が有利
という以前から言われている関係が再度示されただけで,結局 SMPng を持ってしても問題は改善できなかったように思えます.一体 SMPng は何を劇的に改善したのでしょうか?
Re:本当に劇的に改善したの? (スコア:4, 興味深い)
そうですね、グラフには改善前のものが記載されていませんから改善したのか悪化したのかすら判りません。
むしろ、実CPU数よりも多い並列度になるとLinuxのスケジューラはうまく処理を捌けない点に注目すべきだと思います。うまく処理を割り当てていれば、スレッド個別のスループットは落ちたとしても合計のスループットはそれほど低下しないはずです。
FreeBSDにおいて並列4~7度の部分が遅くなっているのは、AMDのCPUを使用していることからリモートメモリへのアクセスが発生していることによるボトルネックに思えます(4で若干低下しているのはOSのオーバヘッドだと考えられます。)。先も書きましたがFreeBSDのスケジューラ/メモリアロケータはNUMAを意識していないように思えます。
Re:本当に劇的に改善したの? (スコア:1)
厳密にはSMPではないとはどの部分を指しているのでしょうか。単にSMPngが対象としている問題領域の範囲内ではSMPとみなせるだけの条件を満たしていたのかもしれません。
それはともかく、実際にはAMDがマシンを提供してくれたから [freebsd.org]でしょう。
NUMA.≠SMP? (スコア:1)
NUMAとSMPは対立する概念とは思えません。
NUMAだからSMPではないとかそういった表現はできなくて、マルチプロセサシステムにおけるメモリの接続方法としてUMAとNUMAといった区分があり、SMPの対義語はASMPだと思うのです。
Re:本当に劇的に改善したの? (スコア:3, 参考になる)
MySQLのベンチにおいて、これまでは全てLinuxを下回る結果でした。
(ソース失念)
改良したULEスケジューラ、libthrスレッドライブラリ、
CURRENTにパッチをあてたもの、という非標準な環境ではあるにしろ
このような結果がでたことは素直に喜ばしいです。
# 6.2-RELEASE の結果も載せるべきだと思う。
Re:本当に劇的に改善したの? (スコア:1, 興味深い)
8CPU上のLinuxでスレッドを増やして落ち込んでいる所よりも下だったんですか?
このグラフを見るとLinuxのこのバージョン(だけと信じたい)のスケジューラには痛いバグがあるというのが無難な結論と思います。
Re:本当に劇的に改善したの? (スコア:1, 参考になる)
2.6.18, 2.6.19, 2.6.20で観測されているよ。
信じたい→無難な結論、って恥ずかしくね?
Re:本当に劇的に改善したの? (スコア:3, 興味深い)
DBサーバに適応すると考えた場合、
このグラフを見る限り普通はFreeBSD改の方がいいという結論になりませんかね?
FreeBSD改のように低負荷の場合に多少性能が悪くても個々のレスポンスが落ちるだけですけど、
Linuxのように高負荷になった場合に途端に性能ががくんと落ちられてしまうと
何かの拍子にネガティブなスパイラルに突入して待ち行列がすごい勢いで伸びていって
「サーバ落ちた」状態になるのが怖そうなんですが。
確かに全範囲でLinuxを上回ればベストでしょうけど、
サーバ関係なら同時リクエストがコア数を上回るなんてザラでしょうから、
そこを優先して改善するというのはアリじゃないでしょうかね。
どうせならスレッド数を対数にしちゃえば良かったのに(笑)と思うAC
(そういえば、昨日のまいにちいっしょ [dokodemoissyo.com]は「グラフで比較すると」ネタだったな~)
Re:本当に劇的に改善したの? (スコア:1)
同感です。
パクリでもいいのでLinuxにもこの研究(実装)成果を取り込みたい物ですね。
(あ、私がBSD使いになればいいのか。)
Re:本当に劇的に改善したの? (スコア:1, すばらしい洞察)
CPU のマルチコア化が進むと、今後は並列処理を積極的におこなうアプリケーションが増えるであろうことが
予想されるので、並列度が低い場合にしか性能を発揮できない事実はうんぬんかんぬん、
ともいえますね。
従来版との比較 (スコア:3, 興味深い)
Re:従来版との比較 (スコア:1)
このグラフを探していました。これを見ると
ということでULEによる効果というわけではなさそうですね。
nopickpriというのが性能向上に大きな効果があるのですが、これは4BSDでは使えないのでしょうね。
filedescがスレッドの競合を防ぐ効果があるように見えることから、Linuxでもまだロックが荒いところがあるように思えます。
末恐ろしいぜマルチコア (スコア:2, 興味深い)
でもその前にメモリ帯域かネットワーク帯域が詰まるんだろうなぁ。
話変わるけど、コア数以上にスレッド走らせても性能的には無意味っていう事に結構おどろいた。
スレッド数がコア数を越えても暫くはスコアが上昇してその後で降下するんだろうなぁ、と何となく考えていたので、コア数越えと共にスコアの上昇がピタッと止まったのは意外。
Re:末恐ろしいぜマルチコア (スコア:2, 参考になる)
LinuxもFreeBSDもスレッドが1つの時は、秒間当りのトランザクションは500だね。
でも、スレッドがコアの数と同じ8になると、両者ともおよそ3000くらい。
4つだと1700くらいだから、たぶん、コア数を0.86乗したあたりが、性能の上限かなぁ?
100コアだとおよそ1コアの52倍の性能あたりだろうか。
ただの推測だし、100コアいくころは、マルチコアの制御の仕方ももっと洗練されるだろうけど。
Re:末恐ろしいぜマルチコア (スコア:2, 参考になる)
FreeBSDのケースは極めて理想に近い性能を示していると言えます。
Re:末恐ろしいぜマルチコア (スコア:0)
>スレッド数がコア数を越えても暫くはスコアが上昇してその後で降下するんだろうなぁ、と何となく考えていたので、コア数越えと共にスコアの上昇がピタッと止まったのは意外。
スループット・レスポンスタイムあたりを混同している予感。
Re:末恐ろしいぜマルチコア (スコア:1, 参考になる)
CPUを使い切ってる状況なら、スレッドを増やしてもスループットの向上なんかは見込めませんが、
例えばディスクの読み込み待ち時間があるとか、CPUが100%使い切れてない状況なら
コア数以上にスレッドを増やすことで、
(同じコア内で、例えば2つのスレッドがディスク待ちと計算処理を交互に行うことになり)
全体のスループットが上昇する可能性がある。
ハイパースレッディングなんかは、そういう状況で(コンテクストスイッチの負荷を減らして)スループットを向上させるような技術だしね。
Re:末恐ろしいぜマルチコア (スコア:1)
それたぶん違う。intelがハイパースレッディングと呼んでるSMTは、パイプラインが長くなってOutOfOrder程度じゃパイプラインが埋まらなくなったので複数のスレッドのコード(=互いに因果関係が全くない)をパイプラインに投入する事でパイプラインを埋める方法じゃなかったか?因果関係のない命令を順番に書いてストールを避けるってのの延長で。
# MMUも複数持たせりゃSMPになるわけだが...。
Re:末恐ろしいぜマルチコア (スコア:1)
Re:末恐ろしいぜマルチコア (スコア:1)
# でもプロセススイッチが絡むとSMTは結構邪魔だったり。特にマイクロカーネルなOSだと困るんじゃないかなー。
他でも再現したみたい (スコア:2, 参考になる)
こっちは4コアに4,8スレッドで比較してますけど、8スレッド時に35%もidleに食われているようです。
やっぱりバグなんですかねぇ。
Re:他でも再現したみたい (スコア:1)
で Suse の人がパッチ出して 30% ぐらいは改善したけどまだまだ、だそうで。
まぁ、あとしばらく見守りましょう。
原因判明 (スコア:2)
素晴らしいことは素晴らしいのですが (スコア:1, 興味深い)
Re:素晴らしいことは素晴らしいのですが (スコア:1)
それ以前にSMP環境でULEスケジューラが安定して動くかどうかって問題もあったり. シングルなら安定して動いてはいるんですけど.
他にもドライバレベルでGIANTロックがまだまだ残っていたり, デスクトップ用途だと割り込みのリアルタイム性がちょっと怪しげだったり(TigerMPXなんか使っているからかも?)とかいろいろあるんで, 実際のシステムで性能をうんぬんする段階ではないという気がしますけどね.
Re:素晴らしいことは素晴らしいのですが (スコア:0)
SMPngもそのうち取り込まれるだろ。
# Vistaの性能がどうこう言ってるときに「アップデートしないXPではどうなんでしょう?」って聞くようなもんだぞ
Re:素晴らしいことは素晴らしいのですが (スコア:3, 参考になる)
ここ [livejournal.com]に出ていますね。
Re:素晴らしいことは素晴らしいのですが (スコア:2, 興味深い)
Re:素晴らしいことは素晴らしいのですが (スコア:3, 参考になる)
http://leaf.dragonflybsd.org/mailarchive/kernel/2007-01/msg00124.html [dragonflybsd.org]
ざくっと、読んでみると、、、
(1) DragonFlyには、まだGiant Lockが残っている。
(2) FreeBSDは、頑張ってるけどやりかたがまずい。あれでは1024CPUは扱えない。
(3) LinuxとDragonFlyは、重点の置き方が違うけど考え方は似ている。
てな話をしている。
Re:素晴らしいことは素晴らしいのですが (スコア:1, 興味深い)
># Vistaの性能がどうこう言ってるときに「アップデートしないXPではどうなんでしょう?」って聞くようなもんだぞ
Vistaはアップデートすると遅くなるんでしょ??
落ち込みは何が原因なんでしょ? (スコア:1, 興味深い)
でも今回の実験だとFreeBSDでは殆ど性能が落ちないんですよね。もっと別のケースのデータなんかも見てみたい気はしますね。
Re:落ち込みは何が原因なんでしょ? (スコア:1)
よしんば別フレームを処理するにしても、DCT系(mpeg2/4/h264等)圧縮だと必要なのは過去(I)、未来(P)、現在(B)の3フレーム分だけで、別フレーム処理するにしても過去、未来は同じなので「広範囲のメモリを参照、大量のI/O」つーほどにはならないはず。
Re:落ち込みは何が原因なんでしょ? (スコア:2, 参考になる)
コアの数を上回ったスレッドを動かすと、個々のスレッドの処理能力は落ちるんですけど、FreeBSDはそれぞれのスレッド処理能力を合計すると、8スレッド動かした時の合計に近い値が出る。
ところが、Linuxは8スレッド超えると、それぞれのスレッドの処理能力を合計しても、8スレッド時の合計に遠く及ばなくなる。
グラフによると、8スレッド動かした時の能力は双方とも、およそ3000。
スレッド毎に375くらいになる。
スレッドの数を16にしても、FreeBSDは能力の合計が3000弱。
合計が8スレッドの時とほぼいっしょなので、スレッド毎の能力は単純に半分になる。
ところが、Linuxの場合、16スレッドになると、能力の合計が800くらいまで落ちる。
スレッド毎には、50程度と激減する。
Re:落ち込みは何が原因なんでしょ? (スコア:1)
シングルプロセサで複数のスレッドを動かした場合、Linuxはやはり性能が低下するのでしょうか。
Re:落ち込みは何が原因なんでしょ? (スコア:1)
性能としてはコア1個に+αといった所で安定します。
性能低下の原因が、単純に、複数スレッドを実行した事にあるのなら、こんな形にはならないと思うんですよ。
これは、複数のコアに対する処理が原因で、最終的には、有効に使えてるコアが1つだけだからなのではないかと思います。
なので、シングルプロセッサの場合、この現象は起きない可能性が高いです。
Re:落ち込みは何が原因なんでしょ? (スコア:1, 参考になる)
> 素のスレッドと言うよりはユーザースレッドだよね。
カーネルスレッドで,I/O待ちに突入した時点で,プリエンプションが起こっているだけでしょう.
DBの処理は,I/O処理と計算処理の粒度が大きいので,カーネルスレッドのベンチマークに最適な例です.
つまりI/O処理待ちの間に,他のスレッドが計算処理を並行して実行できるので
グラフのように実CPU以上のスレッドが起動しても,さほど性能低下が起きていないのだと思います.
MySQLの実装の差とか (スコア:1)
どなたか追試をしていただけるとうれしいっす。
http://ossipedia.ipa.go.jp/capacity/EV0612260303/ [ipa.go.jp]
Re:MySQLの実装の差とか (スコア:2, 興味深い)
http://blog.miraclelinux.com/yume/2007/02/mysqllinux_472a.html [miraclelinux.com]
SMTないしMC用スケジューラの問題だということに落ち着きそうな勢いです。
Re:MySQLの実装の差とか (スコア:1)
解説記事でたよ〜 (スコア:1, 参考になる)
6.Xとの比較も欲しい (スコア:0)
NUMA (スコア:0)
これはNUMA イネーブルなのでしょうか?
Linux は良く解ってないのですが、SMP-ng の対抗馬はNUMA だと思っていたのでAC
Re:NUMA (スコア:1)
逆にFreeBSDはNUMAに対応したスケジューラ/メモリアロケータを持っているのでしょうか。
Re:NUMA (スコア:4, 参考になる)
AMD64 やPPC がNUMA だと言えばそうなのかもしれませんが、NUMA アーキテクチャはサポートしてないと思います。
いちおう、ですが、今日現在のFreeBSD 6.2-RELEASE-p1 は、そもそもULE が有効になっていません。
6.2R 上の同一HW でULE を有効にしたSMP Kernel と
無効にしたもののベンチを採ったところ、全く気にならない程の僅差でULE スケジューラが勝ちました(並列処理数、2,4,8,16,24,32 と試し、その全てでULE の勝ち)。
また、ULE 自体はLinux のスケジューラのパクリといわれていて、実装もソックリです。
http://journal.mycom.co.jp/articles/2005/01/01/ule/ [mycom.co.jp]
MYCOMの記事に酷い曲解をするもんですね (スコア:3, 参考になる)
件のMYCOMの記事には次のように書いてある。
| このCPUごとに複数のキューを持つというこの実装のアイディアは、
| Linux O(1)スケジューラで実現されているものとよく似ている。
つまり、『アイディア』が『似ている』と書いてある。
実際、Linux Kernelを解説する書籍や黒いFreeBSD本を読んでみると実装が大きく異なるのはわかるだろう。
O(1)スケジューラーはrunキュー2つで、ULEはrunキュー2つにidleキュー1つとキューが3つある構成。
このような構造の違いに加え、Linuxの対話的なジョブ判定アルゴリズムを導入したSCHED_COREが最近出来て来たくらいだから、少なくとも対話的なジョブと判定するアルゴリズムはULEとO(1)では異なっている。恐らくはもっと異なっているだろう。
余談だが、FreeBSDのSMP対応の歴史を知りたかったら下記URLのAOSS-2の論文orスライドを読んだら良い。
どちらもULEの話は載っていないが、FreeBSDのSMP対応がBSD/OSを参考にしたと知るには十分だろう。
http://www.lemis.com/grog/SMPng/ [lemis.com]
Re:NUMA (スコア:1, おもしろおかしい)
お金持ちの人は大変だねえ (スコア:0)
で、そのあたりだと以前とどういう差があるんだろ?
Re:お金持ちの人は大変だねえ (スコア:1, 興味深い)
Re:お金持ちの人は大変だねえ (スコア:1, 興味深い)
cgiでP言語起動するなんて言ったら殴られたかもしれない(そもそもp言語いねぇよ)そんな馬鹿なって位のメモリしかなかったんだよな~
今じゃ机の上に2Gバイトの主記憶があるんだものな~、十年一昔なんてレベルじゃねぇやね。
みんなが富豪になったんじゃなくて単なる帝国マルクじゃねぇのかと、当時の自分に小一時間言われそうな使い方だよね。
Re:お金持ちの人は大変だねえ (スコア:3, おもしろおかしい)